Protocols and standards. We live and die by them, and while we can’t live without them, sometimes they can be a royal PITA. And so it is apparently, with Polycom’s interpretation of RFC4568 Session Description Protocol (SDP), with which I became all too familiar this week.
I was called in to try and figure out why a customer’s Polycom VVX’s intermittently couldn’t call out to the PSTN. They could place the call seemingly OK, but as soon as the external party answered it dropped.
Incoming calls were fine, and none of their other clients had any outgoing problems: their Office 2013 and Office 2016 PC clients were fine, as were the fading old CX600’s. Making this scenario all the more interesting is that the PSTN Gateways are NET / Sonus “VX 1200” gateways still running flawlessly from their Lync 2010 days – and still supported by the vendor until the end of 2018 BTW!
Media Bypass is enabled in this environment, so the obvious conclusion to draw was that we were dealing some some kind of incompatibility between the new-ish phones and the (ahem) “mature” VX’s.
Taking “intermittent” to a whole new level
The issue was visible in Lync’s monitoring reports but at a very low frequency: for some users we were talking 12 occurrences in the 15 weeks since January 1st. Their highest performer might have hit 20 in the same period.
This particular “intermittent” fault had a neat trick though: even though it would appear rarely, once it surfaced it STAYED. Every call from that point failed, which the diagnostician in me appreciated because it let me capture traces of the failed calls and compare them with good ones.
Once I had enough traces we just rebooted the phone and it came good again.
Memory leak!
You’re probably already ahead of me: classic symptoms of a memory leak. Reboot the phone and it comes good again, only to fail again a random time down the track. The phones were running 5.6.something when I got to site, so I hit the release note PDFs shopping for the easy cure. Nothing jumped out at me there, so we took the phones on a little firmware roller-coaster ride, first up to the latest UC build (5.7.1.2205), and then in – let’s not call it an act of desperation – back to 5.4. Nope, the issue remained.
We can dupe it!
With some persistence we found we were able to dupe the issue, and despite this being a somewhat tedious exercise it helped us immensely. After each reboot of the phone we found we could make around 100 outgoing calls before it would fail. Thankfully for us we didn’t need to wait for a connect or answer: the arrival of early media was the sign you could hang up and the call counted as a successful attempt. As soon as the ringback tone changed from the phone’s simulated one to whatever was coming from the carrier – or even the pause as it switched over – you could end the call and that added to the count.
In reverse, the failure of the above – the continuation of the phone’s faked ringback tone for more than a burst or two – meant you knew the fault had been triggered and the call would fail.
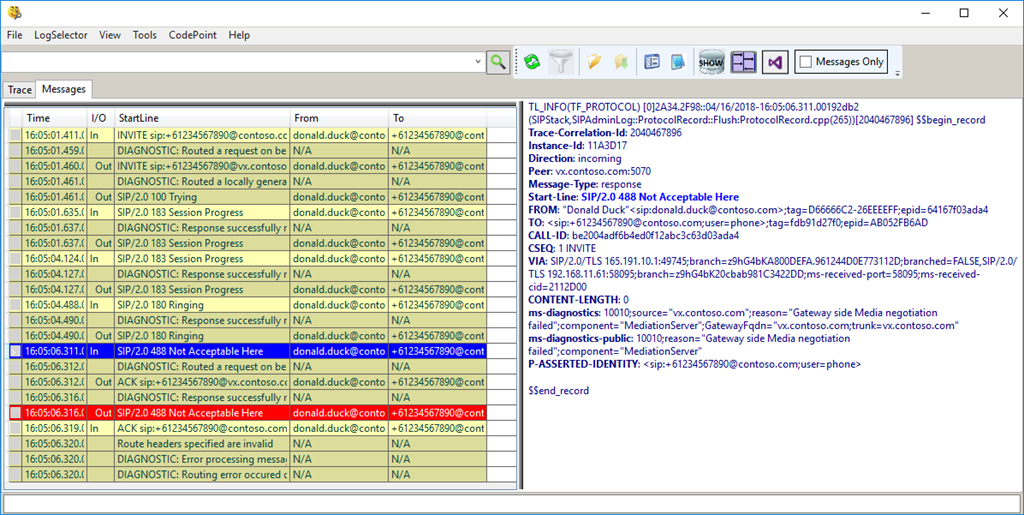
SIP/2.0 488 Not Acceptable Here ms-diagnostics: 10010;source="vx.contoso.com";reason="Gateway side Media negotiationfailed"; component="MediationServer"; GatewayFqdn="vx.contoso.com; trunk=vx.contoso.com" ms-diagnostics-public: 10010;reason="Gateway side Media negotiation failed";component="MediationServer"
Good vs Bad
Comparing good vs bad confirmed that media negotiation was failing. The traces in Snooper revealed that quickly enough.
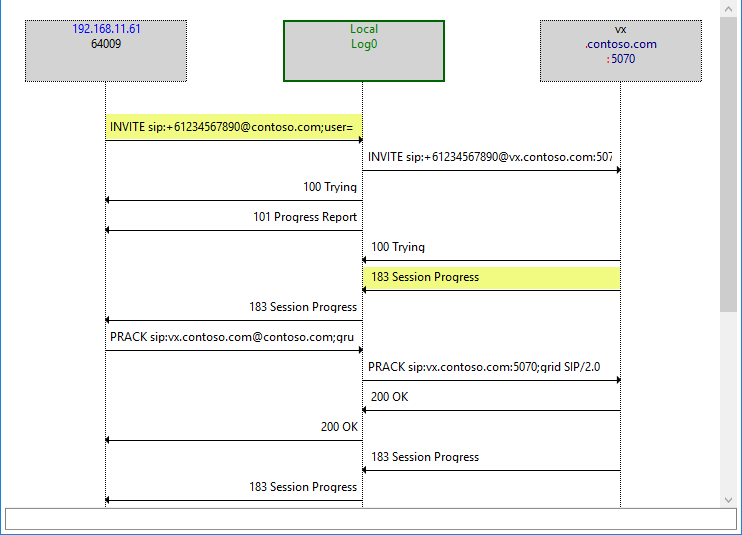
Here’s the ladder diagram of a good call, with the messages containing SDP highlighted. The VX responds to the INVITE with SDP in the 183 Progress message:
In contrast, here’s a bad call, with a slightly different response from the VX to the same initial stimulus:
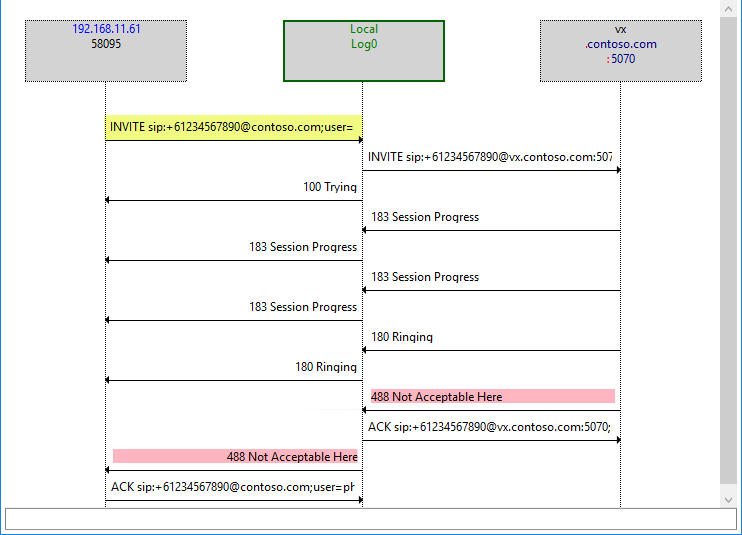
But why – when the INVITE coming in from Mediation is more or less EXACTLY the same?
Once thing that I noticed early on in the piece – but failed to appreciate the significance of at the time – was this difference in the SDP from the phone. Here’s the SDP offered by the phone for a successful call:
a=sendrecv m=audio 2230 RTP/AVP 8 101 a=crypto:9 AES_CM_128_HMAC_SHA1_80 inline:8dUZuUwdbeGZjYqL1YqOCIX1wttjKVimCReMmd0K|2^31|1:1 a=crypto:10 AES_CM_128_HMAC_SHA1_80 inline:UvJt8e9ovkZlAKM+94OXMWoPC15Fvw8p3RSS5Wnn|2^31 a=x-bypassid:1c5fdcc6-c7a0-40d0-b5b3-e6912065f462 a=rtpmap:8 PCMA/8000
And this is the same phone, with a call that is destined to fail:
a=sendrecv m=audio 20022 RTP/AVP 8 101 a=crypto:267 AES_CM_128_HMAC_SHA1_80 inline:CVYLWVqQoxCj8cuxcaT+h+LE9phsibihRE3t34Tn|2^31|1:1 a=crypto:268 AES_CM_128_HMAC_SHA1_80 inline:mKFyewlXtCuUrK+kefahl70lSBP7TECeRLJp/ypk|2^31 a=x-bypassid:1c5fdcc6-c7a0-40d0-b5b3-e6912065f462 a=rtpmap:8 PCMA/8000
Eventually the recurrence of this pattern led me to RFC4568 and the definitions in RFC4234:
9.1 Generic "Crypto" Attribute Grammar
The ABNF grammar for the crypto attribute is defined below:
"a=crypto:" tag 1*WSP
crypto-suite 1*WSP key-params
*(1*WSP session-param)
tag = 1*9DIGIT
crypto-suite = 1*(ALPHA / DIGIT / "_")
So the tag is an up to 9-digit number just to use as a reference or a label that both ends use to refer to the Crypto attribute.
The VVX’s increment the tag from 1 with each reboot, and 2 tags are generated per call attempt, while all our other clients were observed to prefer starting at 1.
The trick is that when the VVX’s tag hits ~200, the VX will ignore the SDP it receives and not offer anything in return. My guess is that someone at NET / Sonus misread the RFC and interpreted the tag’s definition as to mean “a number between 1 and 199”.
We bothered making calls from the VVX until the tag hit 516 and kept climbing, and it was at this point we abandoned that test. (To reach a 9 digit number would take a billion attempts!)
The Fix
The fix (or more correctly the “band-aid”) we settled on was to disable Media Bypass. That resolved the issues on the spot. We saw the Mediation Server soak up the troublesome SDP and generate a fresh SDP with consistently low tags that it sent to the SBC.
An alternative we tested successfully (and was our Plan B) was to disable offering secure media, but the preference was to stay secure even if it meant looping media through the (fortunately) co-located Mediation servers.
<reg reg.1.srtp.enable="1" reg.1.srtp.offer="0″ reg.1.srtp.require="0″ />
Had we gotten to the bottom of the barrel, changing the SBCs back to TCP from TLS would have been a last resort.
The Washup
Everyone loves a good Root Cause Analysis don’t they? Here’s mine:
It certainly looks like the problem is caused by a combination of factors: absolutely it’s a failure of compliance in the VX, but it’s triggered by the one interpretation of the RFC by Polycom in the VVX when all of the other clients follow a totally different approach.
Inspired to shop around, I confirmed that a CX600 (running 4.0.7577.4487) sends the same sequence every call:
a=cryptoscale:1 client AES_CM_128_HMAC_SHA1_80 inline:2Bkh7Lz/xMPzBxzy2fZ2UdHV3A9bU0RWJNvewNpW|2^31|1:1 a=crypto:2 AES_CM_128_HMAC_SHA1_80 inline:U6yedQO/alQhlXLeUVnK4cQKLwtL0TcwRFQOhYXL|2^31|1:1 a=crypto:3 AES_CM_128_HMAC_SHA1_80 inline:ZNSw1V/8hpScjuqTf80NAU+ApnaX3gYabvwMy4+0|2^31
The AC 405HD (running 3.0.1.322) sends just tag 1 each time:
a=crypto:1 AES_CM_128_HMAC_SHA1_80 inline:AsT6Ole4jg2QaNAUN0fl68ArQMtyOcXPCPQT6Ljx|2^31|1:1
Same from a Yealink T48G on 35.8.1.50:
a=crypto:1 AES_CM_128_HMAC_SHA1_80 inline:ZjY2NDQ3NzA0YTgxY2IzNCAzMmI2ZWE3NmEzMzU2|2^31|1:1
My Office 2016 client on 16.0.9126.2116 sends this:
a=crypto:1 AES_CM_128_HMAC_SHA1_80 inline:lycoPaTw310vEH9CrM4KeRkVXjaUHiRVdb2foSeg|2^31|1:1 a=crypto:2 AES_CM_128_HMAC_SHA1_80 inline:qVii+nJtD7kVpx/PsTUbOZKqwHlaUc+v2N78r2Im|2^31
… and the Sonus SBC1000 (running 7.0.1 b483) is happy accepting tags into the 300’s:
a=crypto:305 AES_CM_128_HMAC_SHA1_80 inline:pjlRg5XhZEwuX8mhjTU7CC9W1wf4u3Sr81AJiIOe|2^31|1:1 a=crypto:306 AES_CM_128_HMAC_SHA1_80 inline:F1EBCWKvZUh/hKySoLWc10BI8e2mG0qFcbOVINkr|2^31
Postscript?
The VX is still “supported” by Sonus/Ribbon until the end of the year, so we may be able to get a firmware update out of them to address this apparent failing. The (multiple) VXs in this test were all running 4.9 b44, which I acknowledge is years old. We decided against updating to the current b85 due to the disruption, the risk involved, and the fact that none of the release notes hinted that the problem had been caught and addressed.
References
- RFC4568 – Session Description Protocol (SDP), Security Descriptions for Media Streams
- RFC4234 – Augmented BNF for Syntax Specifications: ABNF
- Habib Mankal – PROXY SIDE MEDIA NEGOTIATION FAILED – POLYCOM VVX CALL TRANSFER FAILURE
Credits
Thanks to Angelo and Ryan who I worked with to nail this one, and to Hab for posting a semi-related blog on a similar subject we should have paid more attention to earlier!
Revision History
25th April 2018: This is the initial post.
– G.




Welk done. Good Description and funny to read. Great