I hit an expected snag recently where I wasn’t able to get an existing SfB 2015 Front-End pool to start after growing it from 1 to 3 servers. Coincidentally I’d performed this same job for another customer maybe a month prior and it had gone off without a hitch. Not so this time.
Try as I might, no amount of resetting the fabric with Reset-CsPoolRegistrarState was going to work; the pool steadfastly refused to start:
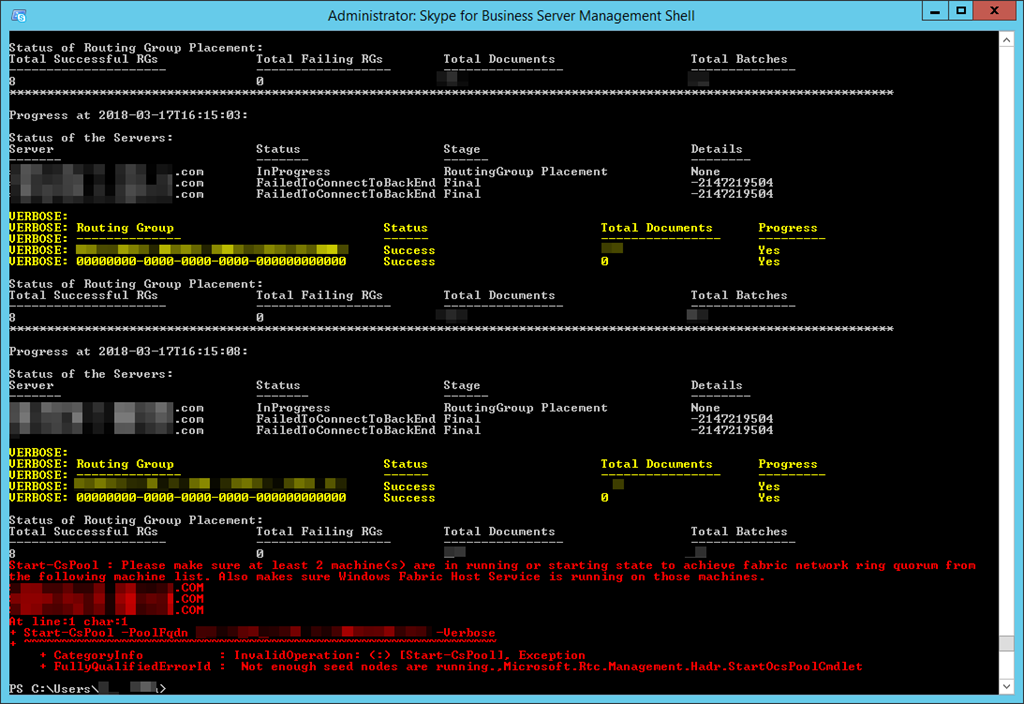
Start-CsPool : Please make sure at least 2 machine<s> are in running or starting state to achieve fabric network ring quorum from the following machine list. Also makes sure Windows Fabric Host Service is running on those machines.
The Status “FailedToConnectToBackEnd” is the critical sign here, and when I had a look at the back-end SQL server, the log was FULL of event 18456:

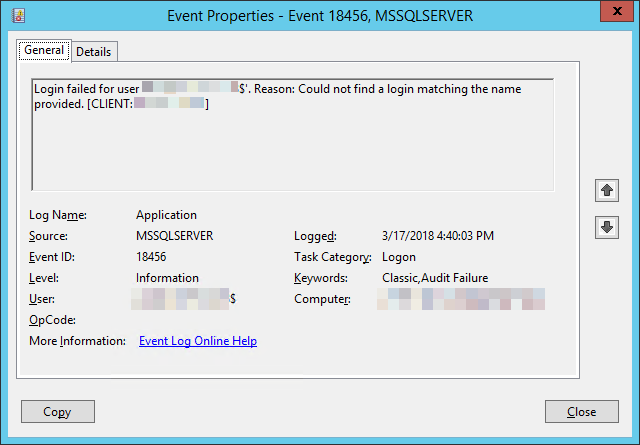
Login failed for user ‘<NetBIOSDomain\Servername>$’. Reason: Could not find a login matching the name provided. [CLIENT: <Server’sIP>]
All of these events named my two new FE’s – over and over (and over) again.
SQL Server Management Studio has no server-specific logins, but *does* give perm’s to various AD groups. Checking all three server accounts in AD revealed all three belonged to exactly the same groups:
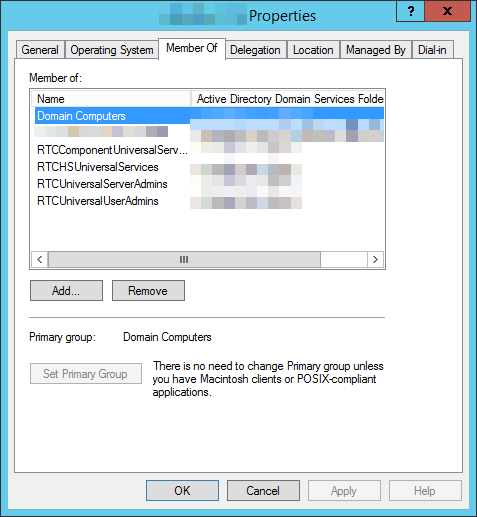
OK, so what’s the difference here?? Head-scratching ensued.
The “Solution”
I’ve lamented before that I’m much happier when I’m playing God in a deployment, with no concerns for permissions problems. Unfortunately this is another of those global corporations where I’m a far-distant minion needing to pull together a deployment with the scraps of permissions tossed at me from on-high.
Taking a punt that I was suffering a permissions problem I deleted one of the new Front-Ends, removing it from the topology, re-running the deployment wizard, then manually uninstalling anything SfB-related that was left on the machine. I then re-added it from scratch, although this time doing so with the local Admin over my shoulder providing his password when I pushed the Topo and as I ran through the Deployment Wizard. The short version: BOOM, we’re up!! I then repeated this for the other new FE and the end result is a happy pool of 3.
I hasten to add that the first attempt at the builds I’d published successfully into the topology without error: only the standard warnings about permissions on the Deleted Objects container. Nothing at all gave me any cause for concern through the installation process either, hence my surprise when the new servers didn’t want to play.
I’m sure others might have been able to determine the specific permission I was missing, but the rebuild got us where we needed to be a lot quicker than raising a support ticket. Hopefully the story helps the next person Googling the error above and at least saves them some time in the diagnosis and recovery.
– G.




Thanks.
I ran into this problem as well. I will try your strategy as I did run into SQL permissions initially but thought I had made it past after I was able to publish the topology the first time by locally login to the ADMIN and granting Sysadmin permissions to my user within SQL.
Late but not least…
Ran into it also, Install-CSDatabase command restored the permissions needed and solved our problem.