Some of Lync’s Client-side error messages don’t really explain the reason for the failure. Here are a few and what they might be indicating. I hope they make your life a little easier:
Instant Messages
“<username> could not be found and this message was not delivered”
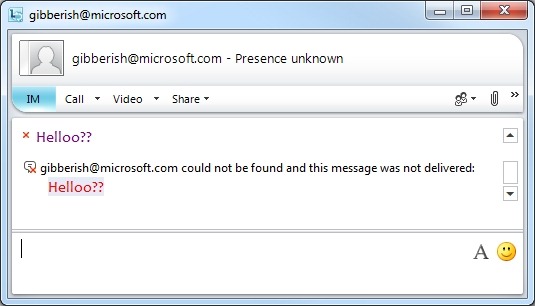
1) There is no such user at the recipient’s domain. There’s an instance of OCS/Lync there, they have an Edge, but you’ve simply nominated an invalid user – or guessed their e-mail naming format wrong.
2) There *is* such a user at the recipient’s domain – but they’re not enabled for Federation. There’s an instance of OCS/Lync there & they have an Edge. [TBC]
3) There *may be* such a user at the recipient’s domain – but they don’t have open Federation and THEY don’t trust YOUR domain. [In this example, my lab domain is not Federated with Microsoft].
“<username> could not be reached and this message was not delivered”
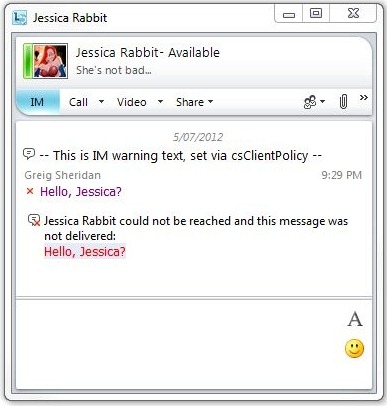
Slightly different to the above: could not be reached, rather than could not be found.
1) Run “Get-CsArchivingConfiguration” and check you’re not set to block IM’s if Archiving fails. Now go check your Archiving server. :-p
“This message was not delivered to <username> because the address is outside of your organization and is not federated with your company, or the address is incorrect. Please contact your support team with this information”
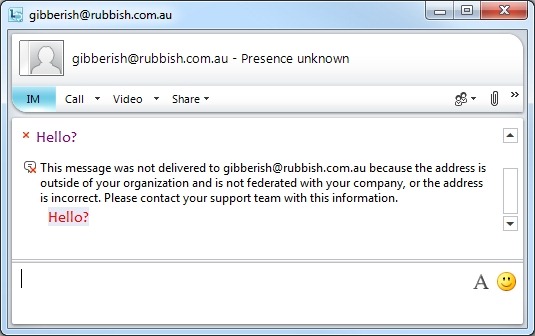
The domain is invalid, is not Lync/OCS, has no Edge/Federation, or your domain is blocked. Take your pick. Please don’t contact your support team with this information!
Error 403
“Forbidden”. You’ve found a valid Lync/OCS user, but they’re not allowed to talk to you. (They’re not enabled for Federation).
“When contacting your support team, reference error ID 504 (source ID 239)”
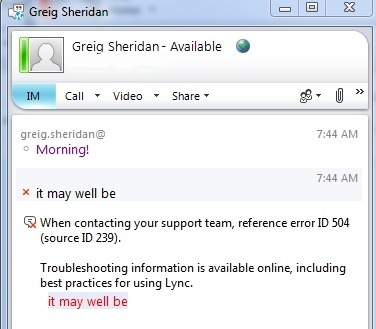
1) If you’re trying to contact a Federated party, your Edge server is down. (Try a different Federated partner to check this).
2) If you’re trying to contact a Federated party, then their Edge server is down. (Try a different Federated partner to check this).
3) If you’re trying to contact a Federated party, this might be because you’ve added a new SBA or Front-End server to your Lync deployment but you’re still using an OCS Edge, and you haven’t added the new server to the Edge’s “trusted servers” list. (All the instances of Error 14502 in the Event Log on the new Lync server are a giveaway too!)
4) Asynchronous routing / bad config. If you can receive IM’s from someone and get this error when you reply, check their system’s external DNS or Edge config. Look for wrong or mis-configured DNS or NAT in the Topology.
5) Check ALL the certificates in the chain between you and the other end. In a recent example, one of the intermediate certificates in the initiating party’s cert chain had been renewed, and this new cert wasn’t trusted by the remote end. Error 14428 on the recipient’s Edge server confirms this issue – “The certificate chain was issued by an authority that is not trusted”. (This is an ongoing drama at the time of writing, as it seems very few Lync Edge servers trust this new intermediate cert).
6) The Edge at the far end doesn’t have a Hosts file entry for that user’s front-End or SBA. (This scenario will manifest itself as “1-way IMs” – you can start an IM conversation with the remote party all OK, but if THEY initiate a conversation to you, YOUR IMs will always receive a 504/239 – but you’ll still receive their messages. This occurs because if you initiate, your establishing IM goes to the remote Edge’s Next-hop server, which IS known to the remote end’s Edge, and from there it’s on forwarded to their registrar).
“This message may not have been delivered to <recipient> because the server sent the message to this person but it timed out.”

This is a Mobility message – but not necessarily an error.
In this scenario, I had switched tasks on my iPhone to another application and ignored the push message that had come through. So I’d received the message OK, but no acknowledgement had gone back to Lync. Similarly, if you lock/close the iPhone and ignore (or simply don’t see) a subsequent push notification, the same will occur. This message is likely to be a cause of some irritation to IT departments around the globe!
Phone/Voice Calls
“+<E.164> cannot answer this call”
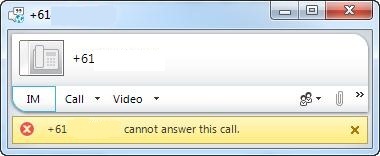
1) Your SIP trunks to the Gateway are down. Perhaps the Mediation server or the SBA is dead?
2) Your PSTN Gateway is dead.
3) Mediation and your PSTN Gateway are UP, but the PSTN/ISDN trunk is dead. [TBC]
“Call was not completed or has ended”
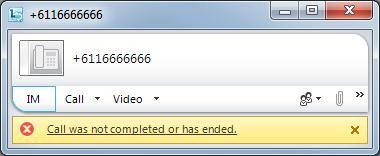
1) There is no route to this number, or you’re not allowed to dial it (it’s not in your Policy). Click the error message and the popup will report “error ID 403” – ‘forbidden’, as above.
2) No available trunk to handle the call. (In this staged example, the one CO trunk on my Tenor ASM200 was in use. The Tenor reported “SIP/2.0 503 Service Unavailable” back to Lync when it gave up).
“Call was not completed or has ended.”
“When contacting your support team, reference error ID 500 (source ID 239).”
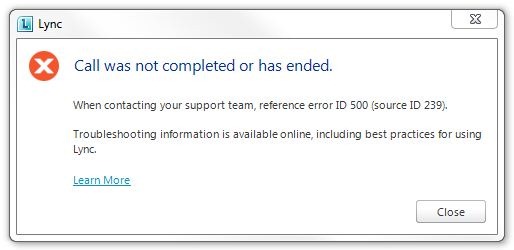
1) We received this when dialling into an overseas conference bridge. The number turned out to be incorrect. It’s not a Lync error.
This is a variation on “Call was not completed or has ended”: “… reference error ID 10001 (source ID 243).”
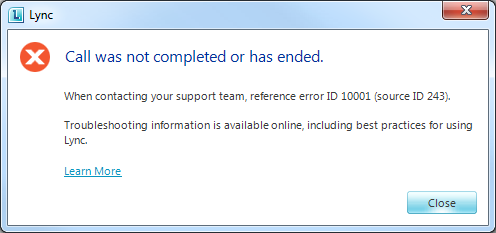
1) In this case, I’d missed a step in the setup. I had all of my ducks in a line: normalisation, usage, policy and route – but I’d not actually specified a PSTN Gateway on the route!
2) I saw this same scenario reported on another Lync as a “ID 403 (source ID 239).” so if that’s your problem, I’d go checking your voice config. Here the “Test Voice Routing” tool might lead you astray: it’s not clever enough to know if you do or don’t have a Gateway assigned to a route.
“Please check the number and try again”

The visual clue in the image is that the number’s not been normalised. This indicates that what the user dialled isn’t catered for in the Dial Plan.
“The call cannot be completed as dialled”

1) A gateway-related problem. (In this staged example, I’d unplugged the trunk from the back of my Tenor ASM200. The Tenor reported “SIP/2.0 400 Bad Request” back to Lync when it gave up).
“+<E.164> is not in service. Please check the number…”
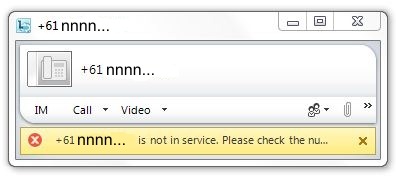
1) In this example it was a (my) RegEx error in the Gateway that resulted in a genuine number being reported as invalid. The Gateway (in this case a UX2000) reported “SIP/2.0 404 Not Found”.
2) My SIP trunk wasn’t registering correctly with the carrier, so all call attempts were being rejected (with “SIP/2.0 404 Not Found”).
“Operation was unsuccessful”
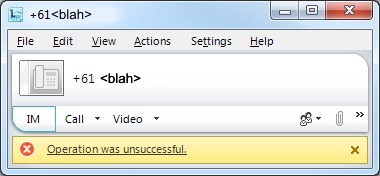
“The calling service did not respond. Wait and then try again. If the problem continues, contact your support team with this information.”
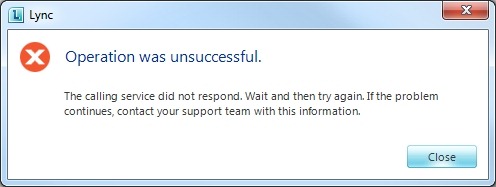
1) In this staged example, the Mediation service on my Front-end was stopped.
2) If you’re trying to call a Federated user and you receive this message, check the Access Edge service isn’t stopped on your Edge server.
“Call failed due to network issues”
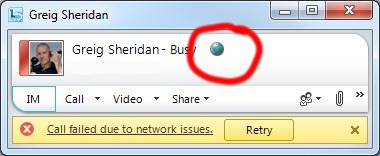
Note the little globe next to the called party’s name – this is a call to a Federated party.
“The call could not connect due to network issues. Try logging out of Lync and logging back in, or try again later.”
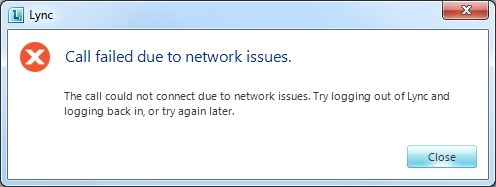
1) This is usually a media issue. If you have presence and IM, but can’t establish media (audio or video) it’s a problem related to the A/V Edge. Perhaps port 3478 and/or the 50k range is blocked, or maybe you have a faulty NAT?
“<username” is unavailable or maybe offline”
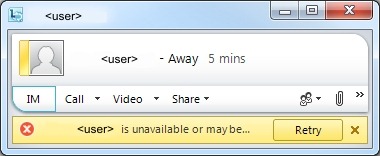
1) They didn’t answer your call, and they aren’t enabled for UM or don’t have any call-forwarding settings enabled.
“<username> did not answer”
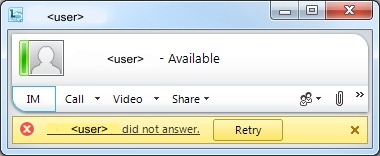
“Call was not completed because <username> did not answer at this time. Try your call again later.”
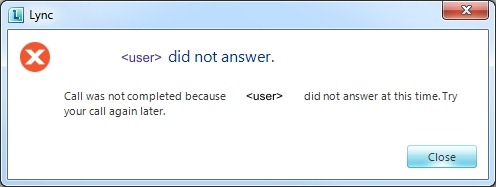
1) Lync is telling a little white lie to protect your feelings. The other party declined your call, but isn’t enabled for UM! (If their status has just coincidentally changed to DND they might have clicked “Redirect / Set to Do Not Disturb”).
“<E.164> did not answer”

I’ve only ever seen this one once, and it’s on a currently faulty SIP trunk service to Australia’s Telstra, through an NET VX1200e gateway.
The call is initiated: we send an INVITE to the carrier, receive a TRYING back from them, followed by a 401 UNAUTHORIZED. I’ll update this post if/when I have some resolution info.
“Call may take longer…”

This one is not strictly an error message, but an indicator that you’ve been blocked by Call Admission Control and are re-routing via the PSTN. (Your voice policy has “PSTN reroute” enabled).
“Could not complete the call because the network is busy. Try again later.”
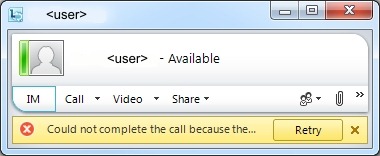
1) You’ve been blocked by Call Admission Control, and either your voice policy doesn’t have “PSTN reroute” enabled, or the called party can’t be reached via that means. Trying again later won’t help if you’re trying to reach a travelling user and the WAN is congested or artificially “CAC-blocked” to force inter-site calls via the PSTN. Your only way of reaching them will be to send an IM and ask them to call you (assuming you’re in your home site and accessible on your DID number) – or call them on their mobile.
“Your microphone is capturing too much noise.”
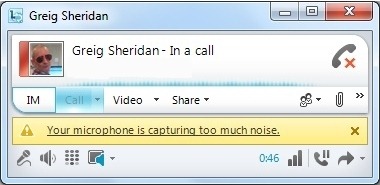
1) You live under the flight path in Sydney, and clearly you’re working from home again. Busted.
Call Park
“Cannot park call right now. Please try again later.”
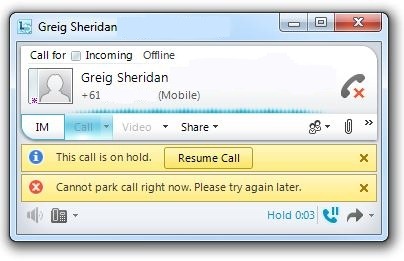
1) This one’s for the “strange but true” category. In this scenario I called in from the mobile via PSTN Gateway A to my Lync user, answered the call and attempted unsuccessfully to transfer it to Call Park. Tracing on the FE and Client were inconclusive, but I kept noticing 503 errors tattling on “Gateway B”, which I’d removed from all my call routes and powered-off but retained in the Topology. Turns out that for some strange reason, Lync wants to talk to the Gateway I’ve defined in the Topology as the Default Gateway prior to parking a call! So, the moral of the story: Don’t turn off the “Default Gateway” in your Topology without selecting a new Default.
The HTML Error codes are taken from this Wikipedia page.




A colleague is receiving the ‘This message may not have been delivered to because the server sent the message to this person but it timed out’ when I am using the Lync client on my iPhone, so we are eager for some help on this error message :)
Hi Troy,
Updated. Please let me know if this message pops in any other scenarios. I’ll try breaking Mobility soon and amend the post to add any other tips I unearth.
G.
I get this one when there are multiple people in the conversation
Also, this is on the Lync Client on the pc!
Hi Lewis. Are your servers all patched to current (CU8) and you’re running the latest version of the mobile client?
What about “Call failed due to Network Issues” … Did you figure that out ? Please do explain this … I’ve been struggling with this error since 2 days, whenever I make audio/video calls with external users, the call lasts for 5 seconds and then disconnects, giving the above error.
Thanks
Hi B,
No, sorry, I’d actually forgotten to revisit that one. For that I’d:
1) Turn on client-side logging (Tools/Options/General: “Turn on logging in Lync”)
2) EXIT Lync completely (not just logout)
3) Navigate to C:\users\<username>\tracing\ and delete (or rename) the file *.uccapilog
4) Launch Lync
5) Repeat your failed test scenario
6) Exit Lync
7) Browse the now much smaller and useful log file (Notepad++ is good, or if you have an x64 o/s, Snooper.Exe). Look for the “a=candidate” lines and confirm that you’re able to reach the other party on at least ONE of the IP addresses listed there. And if you can, make sure the port’s open as well. The protocol workloads poster (http://www.microsoft.com/download/en/details.aspx?id=6797) is a brilliant resource here, as are the edge reference topology articles on TechNet (http://technet.microsoft.com/en-us/library/gg412898.aspx?ppud=4).
Happy hunting. Let me know how you get on!
– G.
Thank you Greig, I enabled logging in the clients and found this in the logs ” Call failed to establish due to media connectivity failure when one endpoint is internal and the other is remote” … I’m working in a test environment, My Firewalls are all open, I double checked my DNS records and certificates … all seems to be fine, but in the Lync control panel I noticed that the “Access external SIP port: Not set” in the edge server service details, could that be the problem? and how do I set’t ?
Thanks
Hi Greig,
I’m receiving this “Call was not completed because did not answer at this time. Try your call again later.” error when I make a call to a land line from Lync (not Lync to Lync), but I do receive calls from land lines. What could it be?
Thanks.
Hi Bileps!
Is this a reproducible fault, and does it happen only from your account, or from all accounts? Is it TO a given destination, or all destinations? Does it happen as soon as you dial, or only after so many seconds of ringback tone?
I’d be looking to your gateway first off. Are you using traditional PSTN/ISDN or a SIP trunk? Compare the ISDN or SIP messages incoming from a good call with a failed one. Perhaps there’s a message translation problem?
G.
Hi Greig,
It happens from all accounts, when we call to telephones (not mobile ones) and as soon as I dial.
We are using a SIP trunk. I’ll check the messages.
Thanks.
Greig,
Could you give me any tip to solve this?
thanks.
Tracing the SIP flow should give you some indication as to what’s going on, but without that and some more info on your config I’d really be shooting in the dark as to what your problem might be. (I only have 1 customer here even using SIP Trunking, and they’re going through an NET VX Gateway to give us greater control over the signalling…)
I suggest you trace one of these calls with the Lync Server Logging Tool and write down (or draw) the SIP messages being sent between Lync and the carrier. Identifying the error message you’re getting back from the carrier may help you understand the problem.
Can your Gateway provider (if you’re using one) or the carrier provide a recommended config for Lync?
G.
Hello,
I would like to talk about a Lync issue I was having the other day that is listed here, but different circumstances. The issue I am talking about is: “This message may not have been delivered to because the server sent the message to this person but it timed out.”
The problem that was occurring was internal communication between our Edge server and there rest of the network was hampered. The timeout was the result of the request getting to the edge server and then not being able to go any farther.
The firewall terminating the connection is what gave the time out error. The edge server would just keep querying until timeout.
Thanks,
MasterZax
Hi Greg. My colleague can use Lync video and audio calling fine on his iPad but if he logs into Lync on his Macbook and someone calls him he sees everything as per normal, but clicking on the green “connect” icon does nothing. Icon shows as “active” i.e. is not greyed out, but nothing happens. Similarly if he rings out to someone and they click on the connect icon nothing happens. Result is that call rings out. Has re-booted machine a number of times and re-loaded Lync application, all to no avail.
reference error ID 450 (source ID 239) a message was not delivered and got this error.
Awesome site! I am getting a scenario where I can Lync one on one, but the second a 3rd person joins the call, all voices are immediately garbled. I am new to Lync and just can’t figure out what to look for.
THanks!
Muy buenas tardes, el communicator del mac presenta problemas, a la hora que realizo una conversación con varias personas no se permite crear la conversación y después de varios minutos presente este mensaje. “no se entregó a todos los participantes porque no hubo respuesta del servidor”