I noted in my recent post about CU4 that I’d seen a recurrent 32270 error in my Lab after the install, and that it took another reboot to banish.
Roll forward a few weeks to my current customer deployment and I’ve been seeing recurrent PDP (Call Admission Control) errors… since the moment CU4 went on.
These are popping out roughly every 5 minutes:
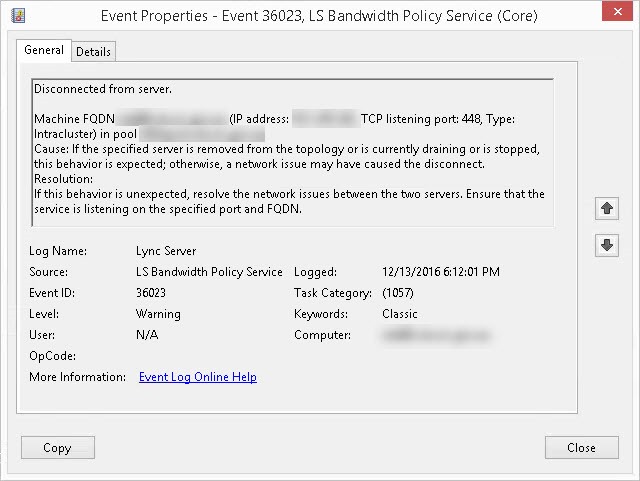
Event 36023, LS Bandwidth Policy Service (Core) Disconnected from server. Machine FQDN server1.contoso.com (IP address: 10.10.10.10, TCP listening port: 448, Type: Intracluster) in pool myfepool.contoso.com Cause: If the specified server is removed from the topology or is currently draining or is stopped, this behavior is expected; otherwise, a network issue may have caused the disconnect. Resolution: If this behavior is unexpected, resolve the network issues between the two servers. Ensure that the service is listening on the specified port and FQDN.
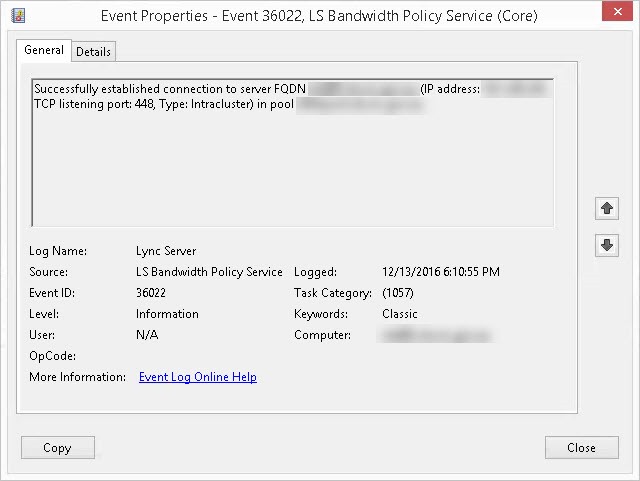
Event 36022, LS Bandwidth Policy Service (Core) Successfully established connection to server FQDN server1.contoso.com (IP address: 10.10.10.10, TCP listening port: 448, Type: Intracluster) in pool myfepool.contoso.com.
A reboot would have probably fixed it, but I wanted to avoid that across my EE pool, so I tickled the PDP services on all three FEs and the error’s gone.
stop-csWindowsService RTCPDPAuth stop-csWindowsService RTCPDPCore start-csWindowsService RTCPDPCore start-csWindowsService RTCPDPAuth
Fixed in CU5
I guess I wasn’t the only one encountering this as it’s been subsequently addressed by a KB in the May 2017 release of CU5:
- 4020994 Event ID 36023 is consistently logged on Multiple Front-End servers in a Skype for Business Server 2015 environment that enables CAC
Revision History
3rd June 2017: Added “Fixed in CU5”.
– Greig.



